Oi=j∑∑jS(Qi,Kj)S(Qi,Kj)Vj
首先,为了解决时间空间复杂度是平方的问题。
通过之前的研究,可以有这种方法。
S(Qi,Kj)=ϕ(Qi)ϕ(Kj)T
Oi=∑j=1N(ϕ(Qi)ϕ(Kj)T)∑j=1N(ϕ(Qi)ϕ(Kj)T)Vj
(ϕ(Q)ϕ(K)T)V=ϕ(Q)(ϕ(K)TV)
就是找到合适的核函数 ϕ 来模拟逼近 Softmax
由于矩阵的运算顺序变得可交换,来缩小运算量

使用了这几种来做对比
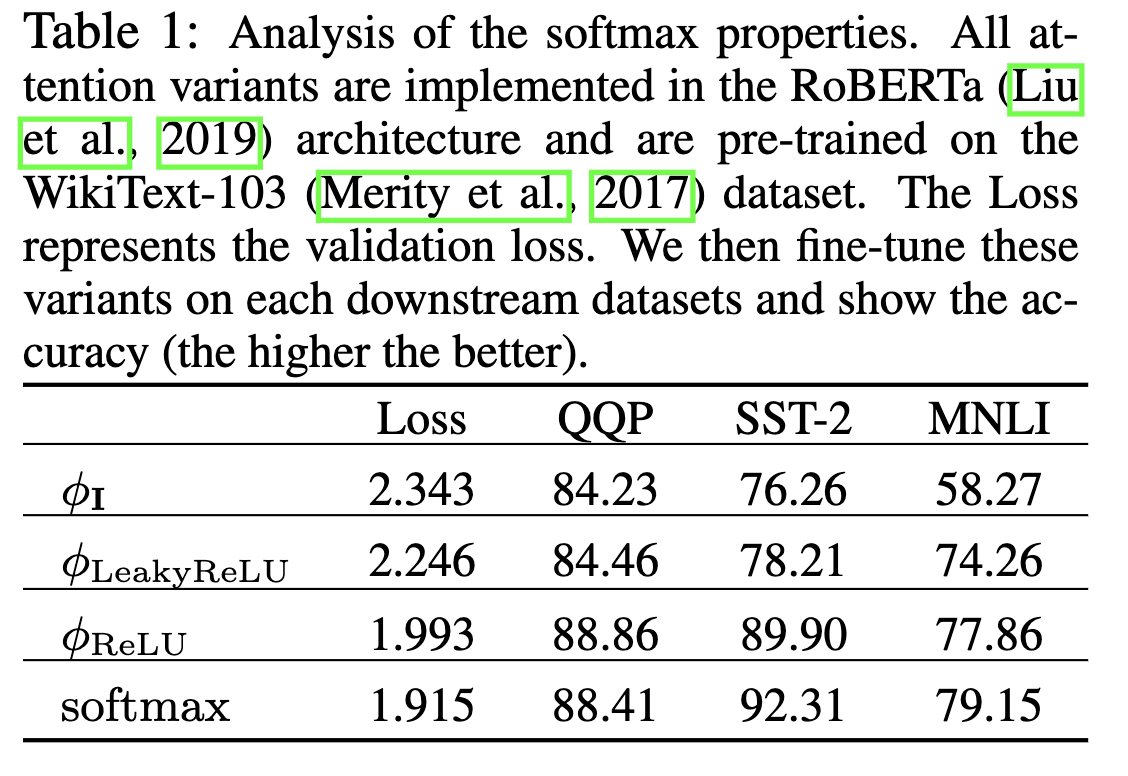
所以本文最后选取了 ReLU
S(Q,K)=s(ϕlinear (Q),ϕlinear (K))=s(Q′,K′)
ϕlinear (x)=ReLU(x)
Oi=∑j=1Nf(ϕlinear (Qi),ϕlinear (Kj))∑j=1Nf(ϕlinear (Qi),ϕlinear (Kj))Vj=∑j=1N(ReLU(Qi)ReLU(Kj)T)∑j=1N(ReLU(Qi)ReLU(Kj)T)Vj
Oi=ReLU(Qi)∑j=1NReLU(Kj)TReLU(Qi)∑j=1NReLU(Kj)TVj
在 Softmax 注意力中引入非线性重加权机制可以聚集注意力权重的分布,因而稳定训练过程。研究者还通过实证发现,这种做法可以惩罚远距离连接,并在某些情况下加强局部性。
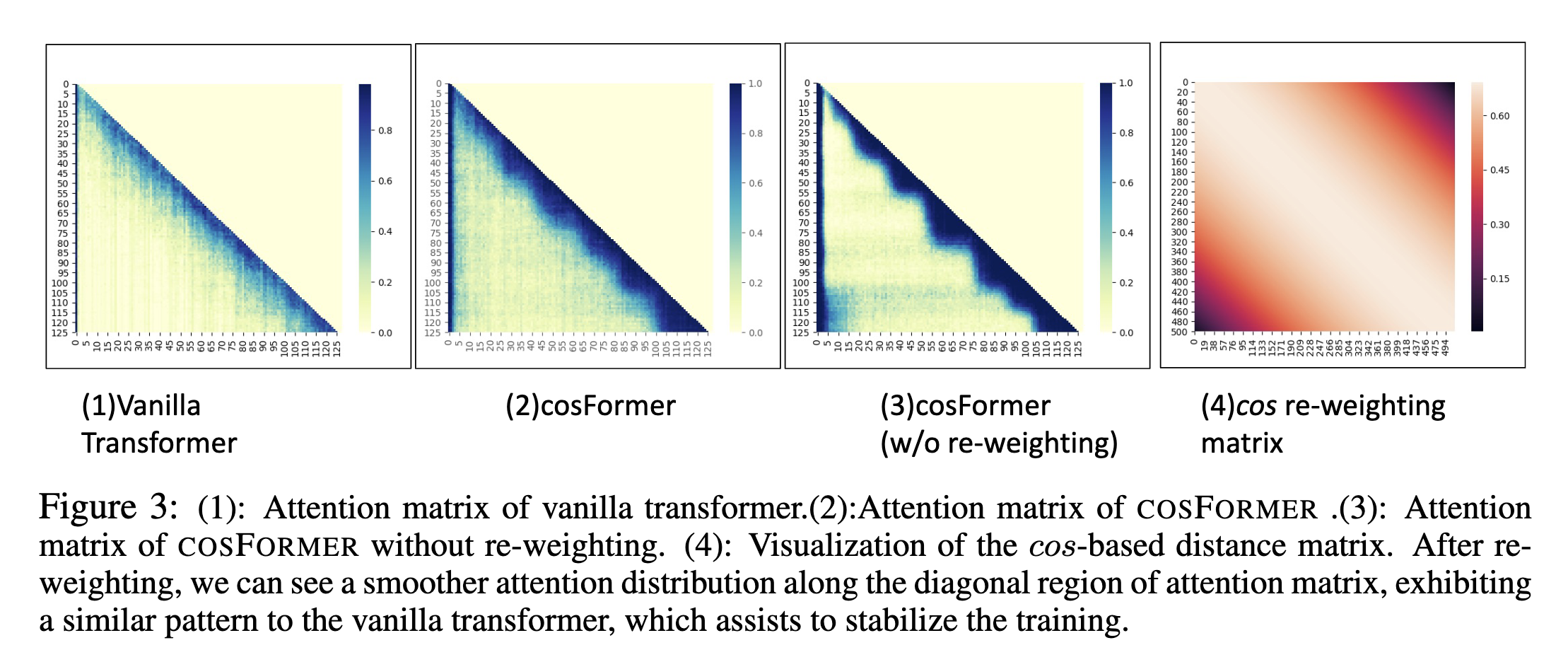
所以需要加强局部性,提出一种 re-weight 方法来加强。
s(Qi′,Kj′)=Qi′Kj′Tcos(2π×Mi−j)
Qi′Kj′cos(2π×Mi−j)=Qi′Kj′T(cos(2Mπi)cos(2Mπj)+sin(2Mπi)sin(2Mπj))=(Qi′cos(2Mπi))(Kj′cos(2Mπj))T+(Qi′sin(2Mπi))(Kj′sin(2Mπj))T
Oi=∑j=1Nf(Qi′,Kj′)∑j=1Nf(Qi′,Kj′)Vj=∑j=1NQicos(Kjcos)T+∑j=1NQisin(Kjsin)T∑j=1NQicos((Kjcos)TVj)+∑j=1NQisin((Kjsin)TVj)
O=S(Q,K)V=(QcosKcos+QsinKsin)V=Qcos(KcosV)+Qsin(KsinV)
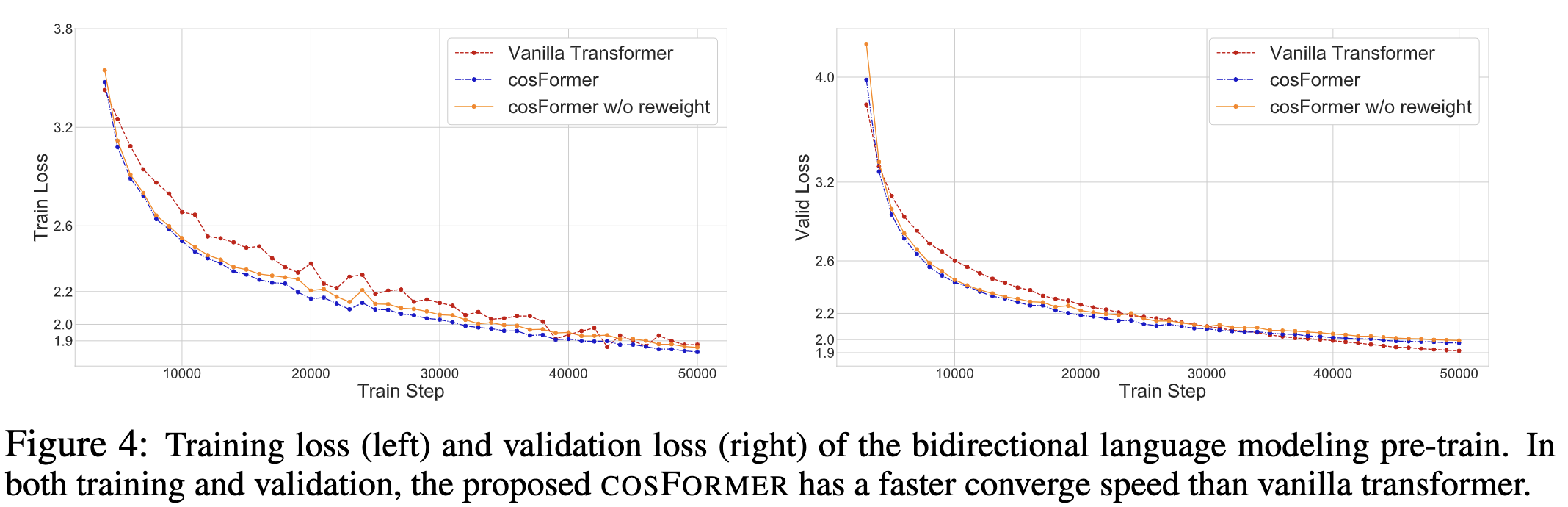
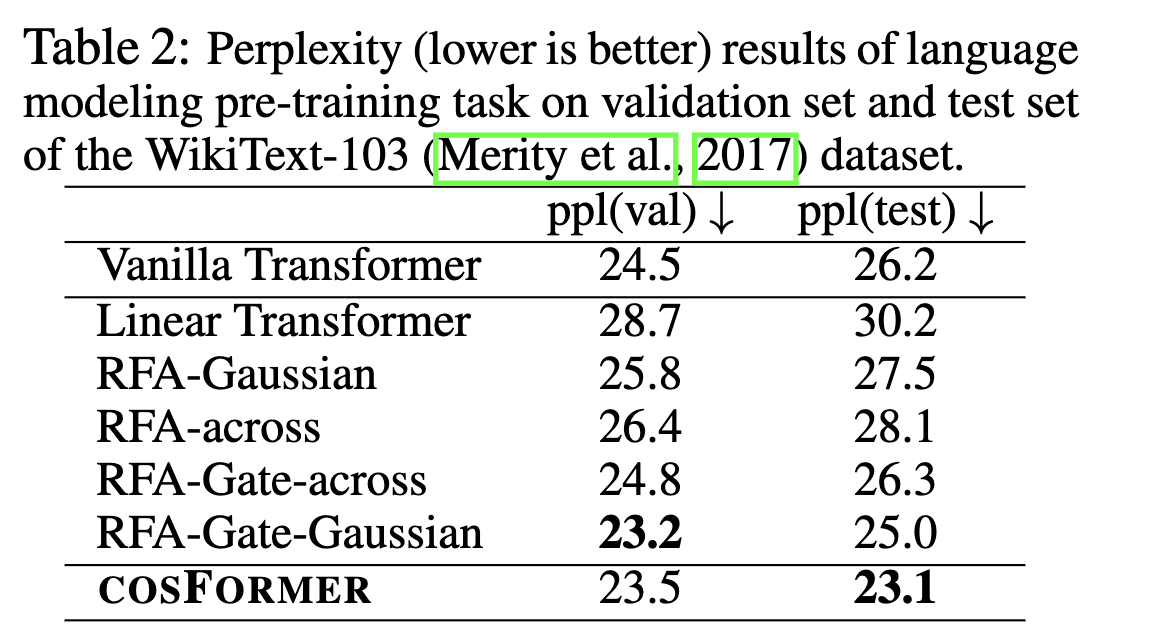
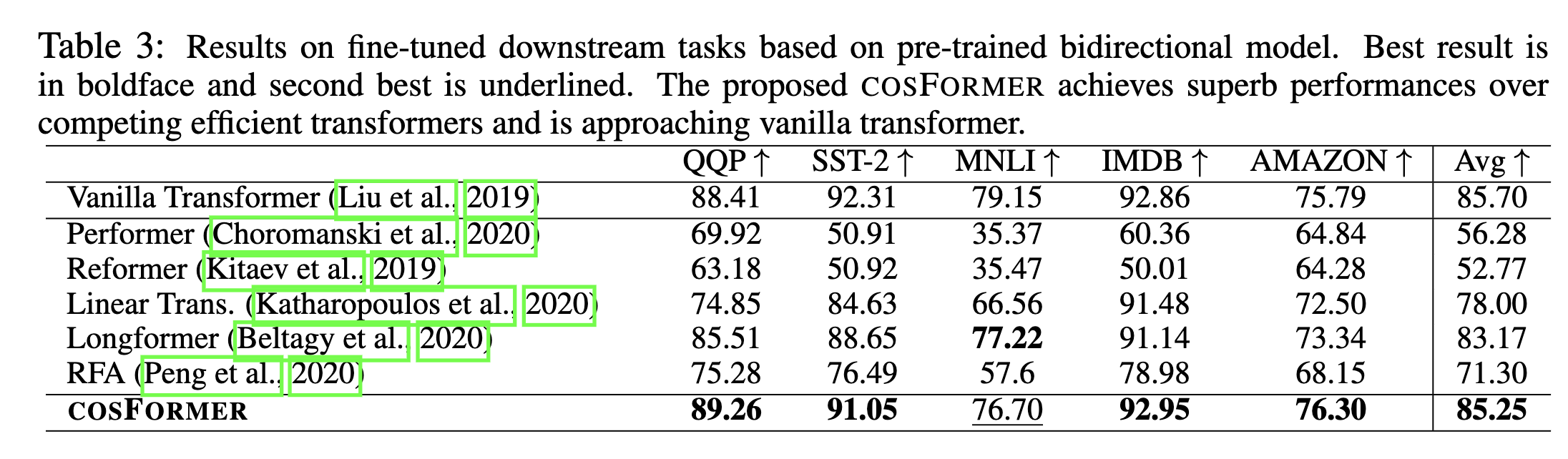
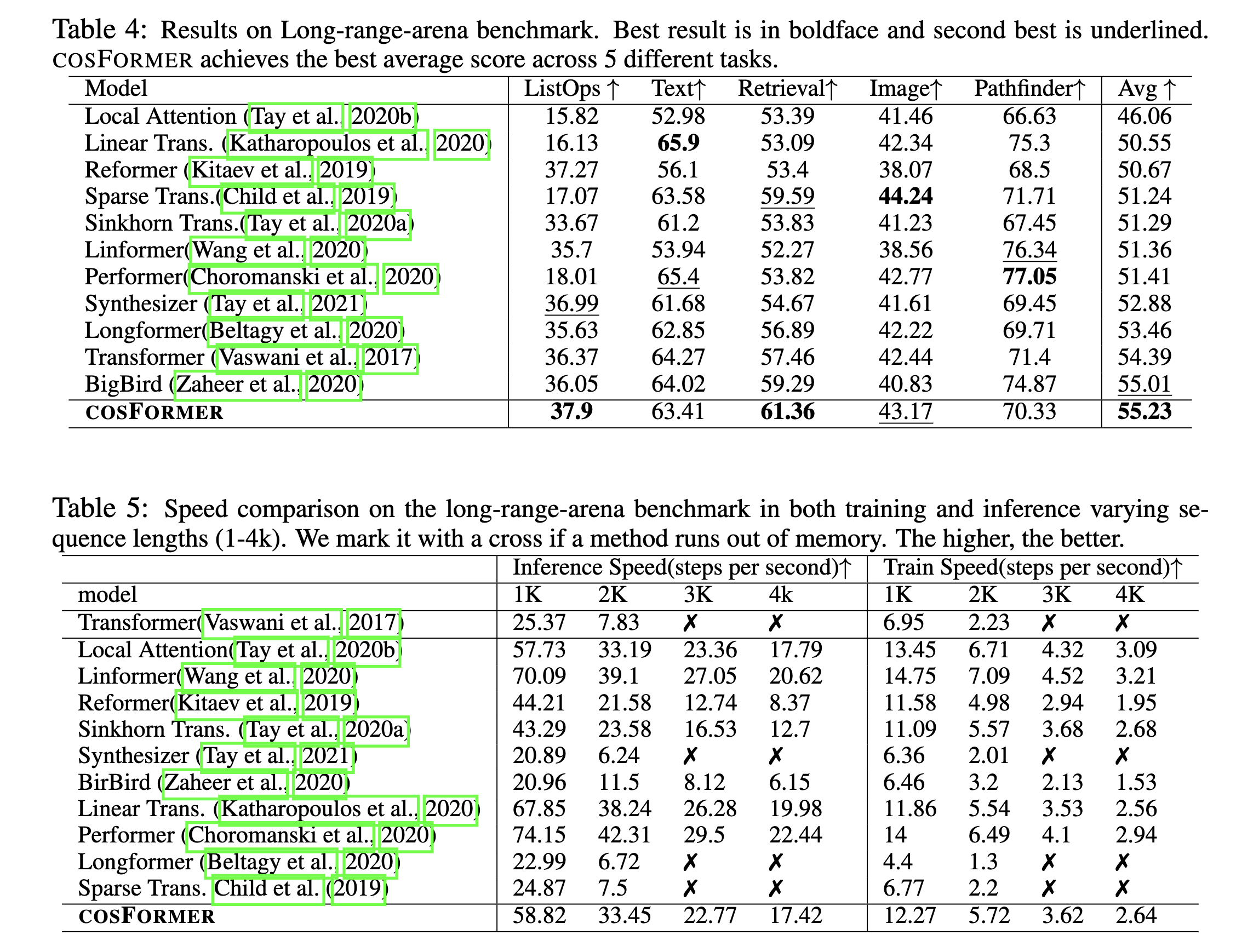
也通过实验来验证了 这种做法的有效性。
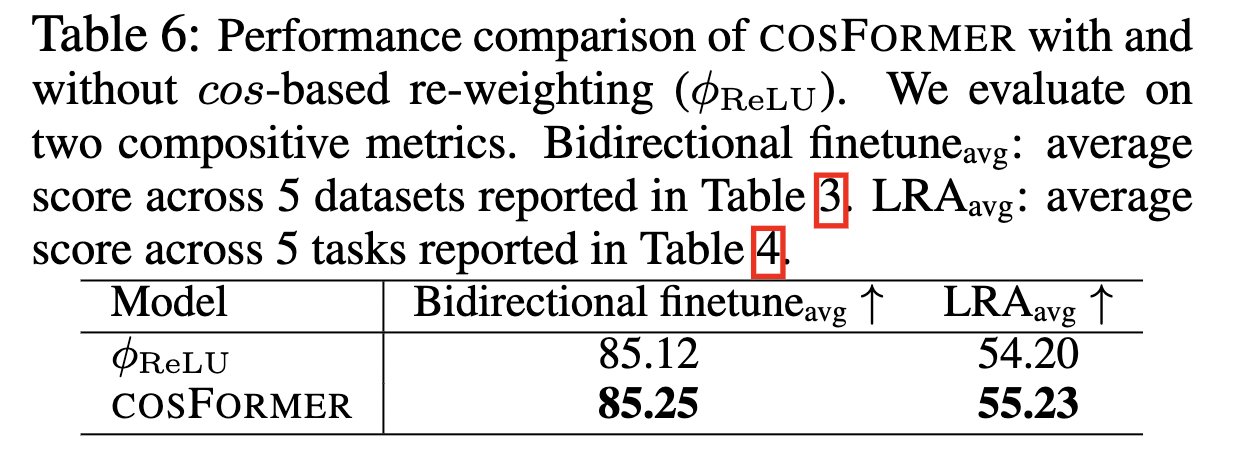
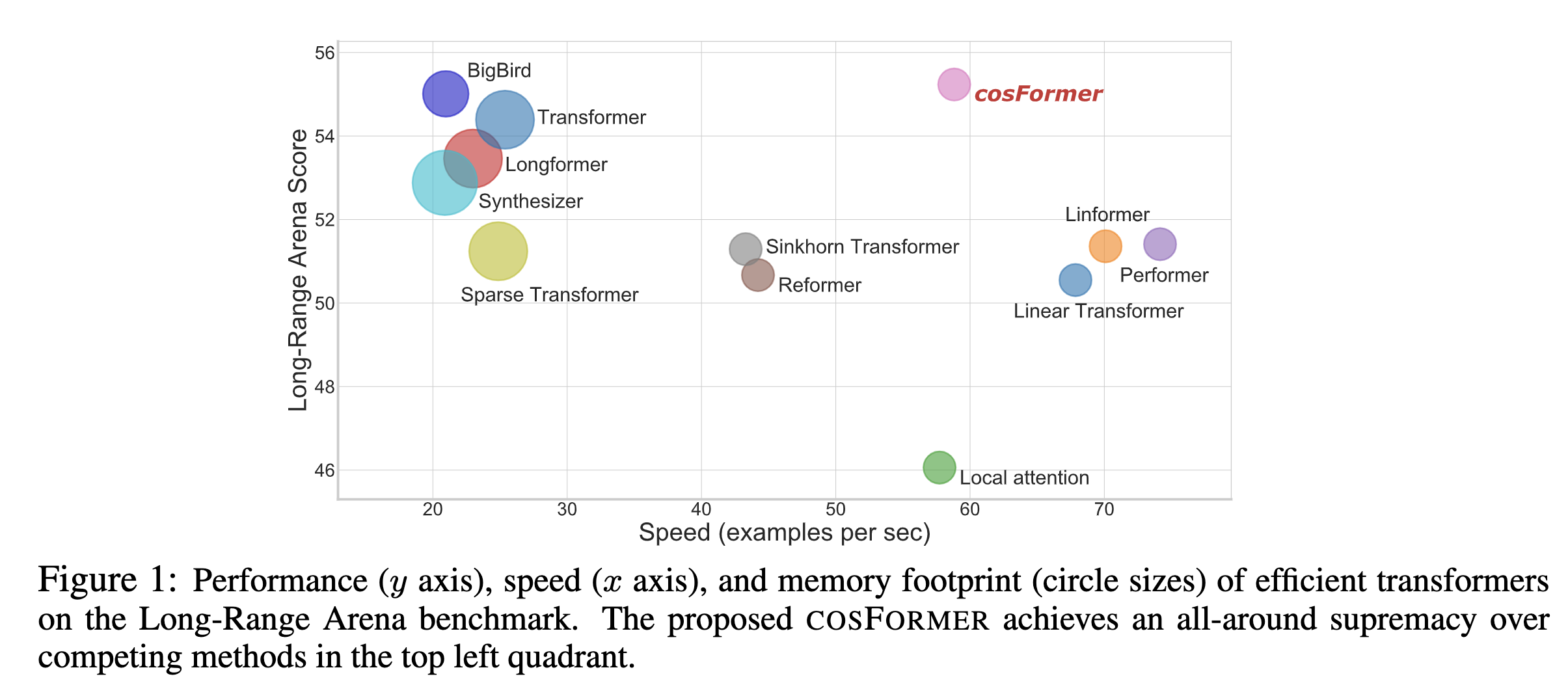
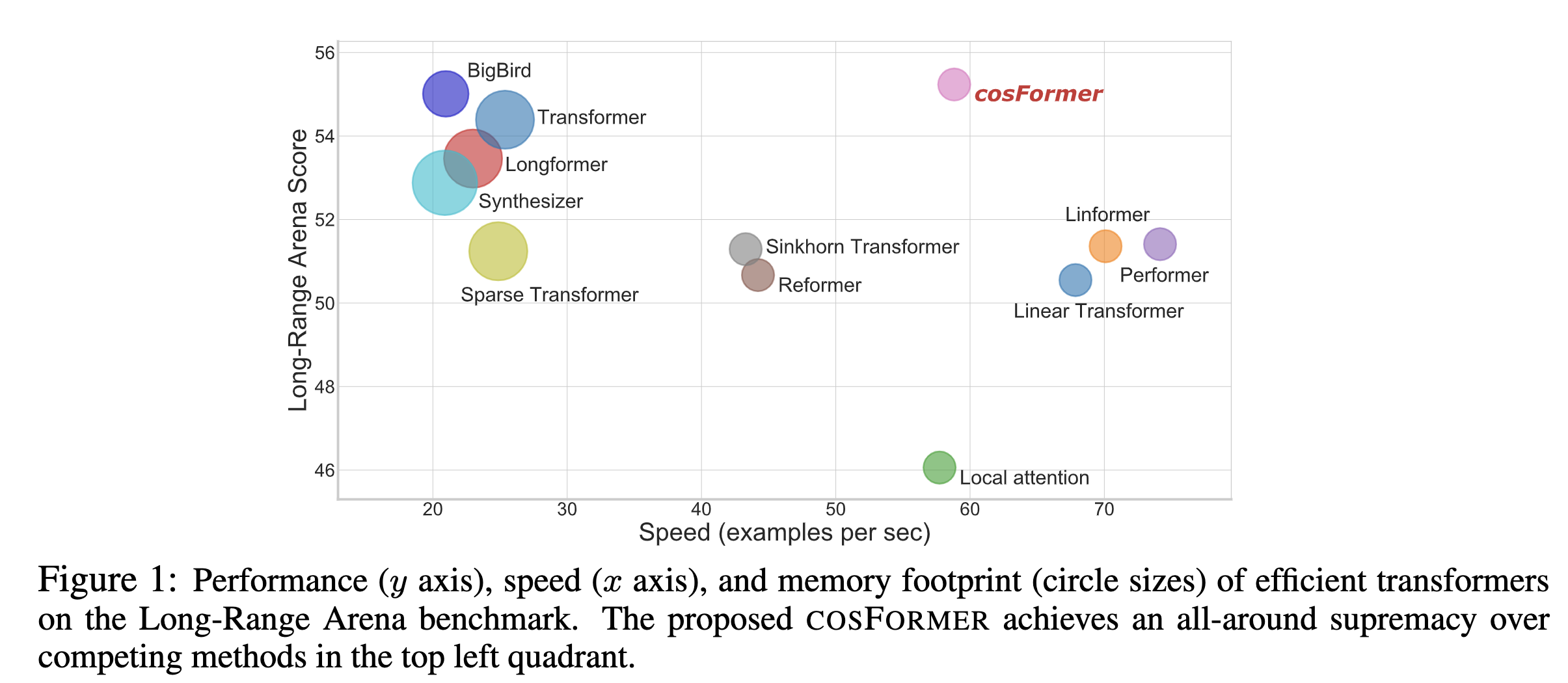
最后效果如下