DeepNet: Scaling Transformers to 1,000 Layers
深层 Transformer 不稳定
更好的初始化方法可以让 Transformer 的训练更稳定。
新的归一化函数
DeepNorm
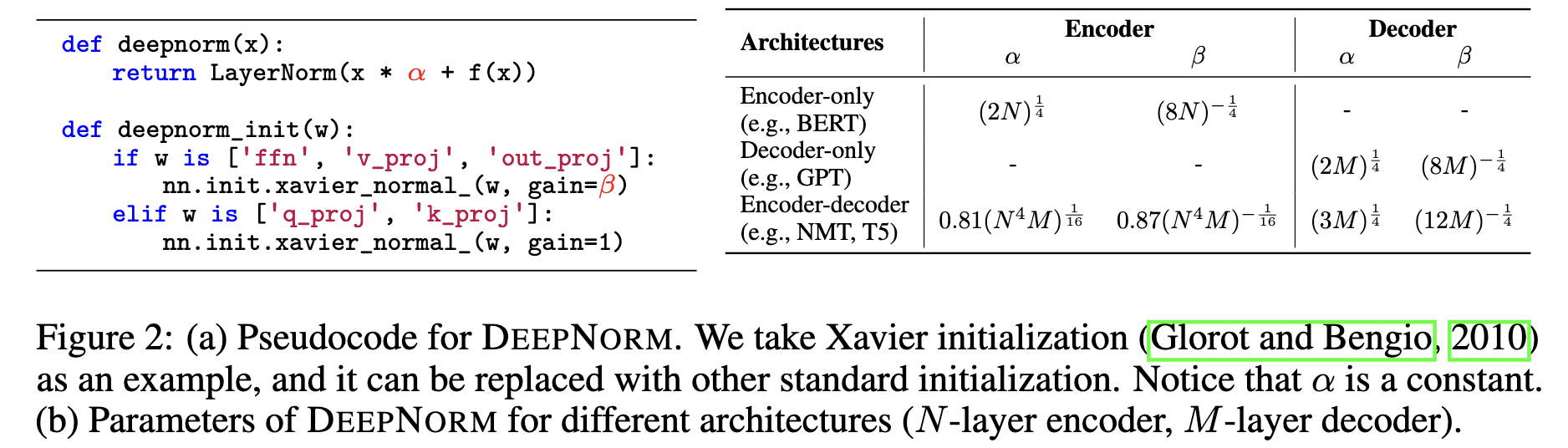
利用这个新的初始化方法来初始化参数,使得模型在训练时候可以更加稳定。
Post-LN 与 Pre-LN
[[Post-LN]]
保证了主干方差恒定,每层对 x 都可能有较大影响,代价则是模型结构中没有从头到尾的恒等路径,梯度难以控制。通常认为会更难收敛,但训练出来的效果更好。
[[Pre-LN]]
第二项的方差由于有 norm 是不随层数变化的,于是 x 的方差会在主干上随层数积累。到了深层以后,单层对主干的影响可以视为小量,而不同层的 f 统计上是相似的,于是有
深层部分实际上更像扩展了模型宽度,所以相对好训练
[[Deep-Norm]]
通过参数控制起了一个折中的效果
也可以说是 增强了主干的占比和重要性 从而使得在优化这种深层模型时候更容易进行优化和训练(即更加容易收敛)