ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
所提出的ERNIE 2.0除了能够捕获预训练语言模型中常见的句子或者词的共现之外,更重要的是能够捕获词汇、句法和语义信息。
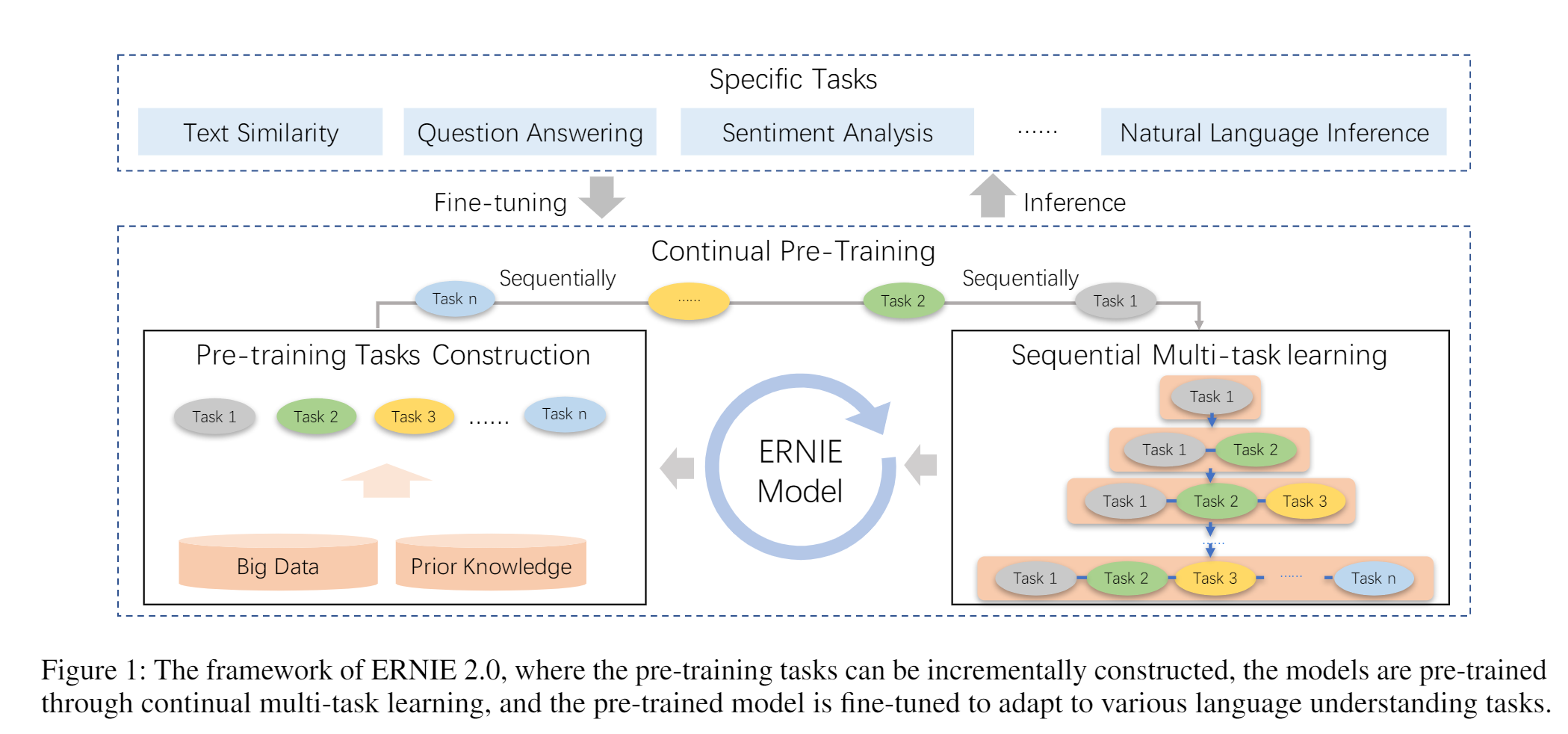
提出一种持续学习的方法。本文框架是在一个持续的学习模式中训练所有这些任务。本文会先用一个简单的任务训练一个初始模型,然后不断引入新的预训练任务对模型进行升级。对于一个新任务,先用前一个任务的参数进行初始化。然后,新任务将与之前的任务一起训练,以确保模型不会忘记它所学到的知识。
Task Embedding
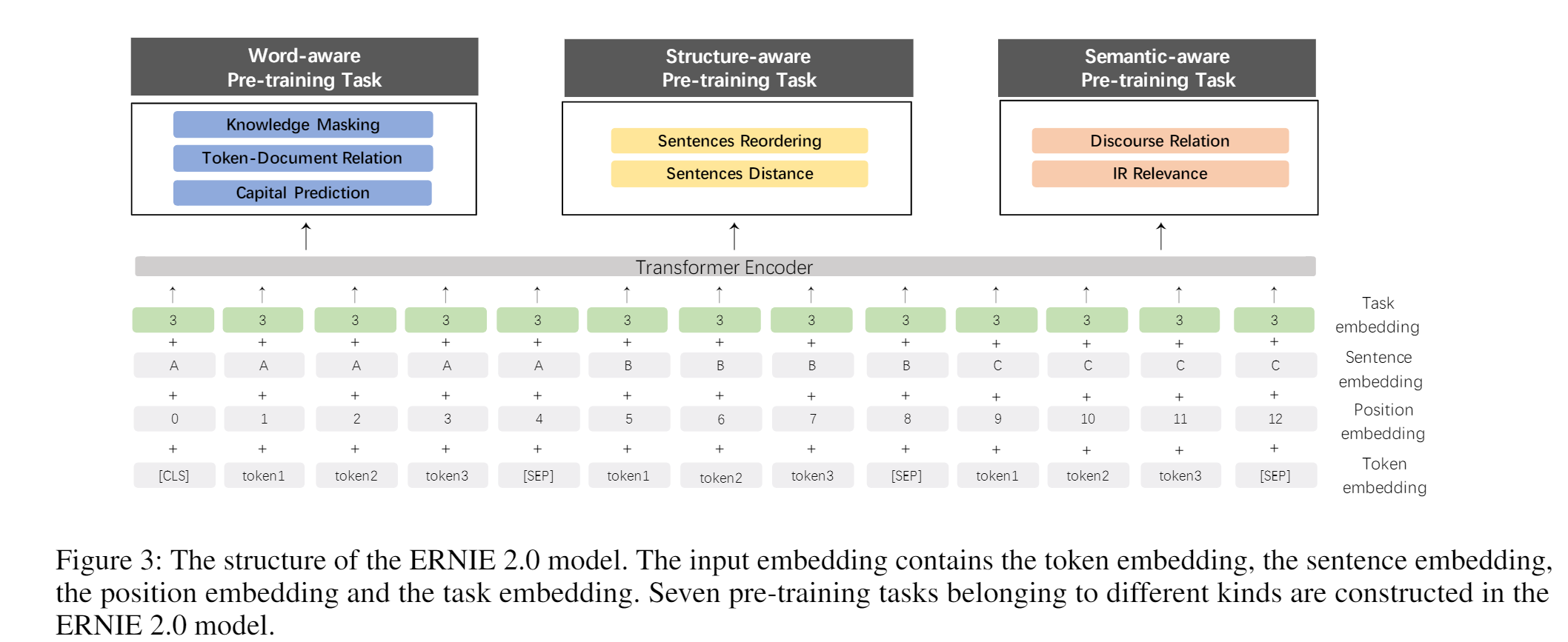
模型中的task embedding是用以适用不同特性的任务。N个任务分别记为0~N,每个任务id有其特定的task embedding。具体来说,每个任务都有其特定的token embedding 、position embedding和task embedding作为模型的输入。在微调阶段,可以选用任意一个任务id来进行模型的初始化。
模型具体做法
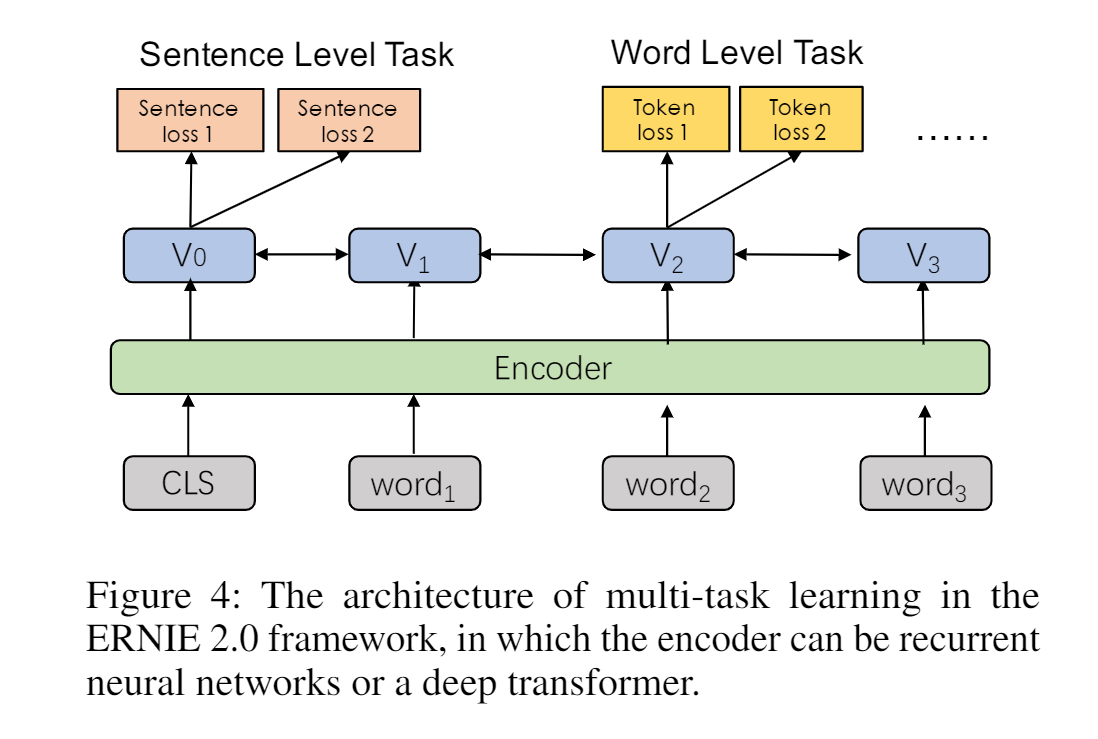
首先训练的时候先对某个任务进行训练,然后再往模型中不断加入其他任务,优化的 loss 是所有任务的 loss。
训练的时候有三种不同级别的任务。
- Word-aware Pre-training Tasks
- Knowledge Masking Task:像 ERINE 1.0 里面提出的那样做 mask 的做法。
- Capitalization Prediction Task(首字母大写预测)
- Token-Document Relation Prediction Task:预测段中的token是否出现在原始文档的其他段(segment)中
- Structure-aware Pre-training Tasks
- Sentence Reordering Task:句子重排任务是为了学习句子之间的关系。
- Sentence Distance Task:这个任务是希望通过文档级的信息学习句子之间的距离。该任务是一个3分类问题,0表示在同一个文档中2个句子是近邻;1表示2个句子在同一个文档中,但是非近邻;2表示2个句子来自不同文档。
- Semantic-aware Pre-training Tasks
- Discourse Relation Task:除了上述的距离任务,还引入2个句子之间语义或修辞关系的预测任务。对于英文任务,采用Sileo et.al构建的数据集进行模型的预训练。对于中文数据集,采用Sileo et.al的方法,本文也自动构建了一个中文数据集用于预训练。
- IR Relevance Task:这是一个3类别的分类任务,用于预测query和title之间的关系。将query作为第一个句子,title作为第二个句子。0类别表示,query和title是强相关的,这意味着输入query后该title被点击了;1类别表示,两者是弱相关的,这意味着query输入后,搜索引擎返回的title没有被点击;2类别表示,query和title是完全无关的,二者在语义上是随机的。PS:百度搜索引擎的搜索日志作为预训练数据集。