ERNIE 3.0: LARGE-SCALEKNOWLEDGEENHANCEDPRE-TRAINING FORLANGUAGEUNDERSTANDING ANDGENERATION
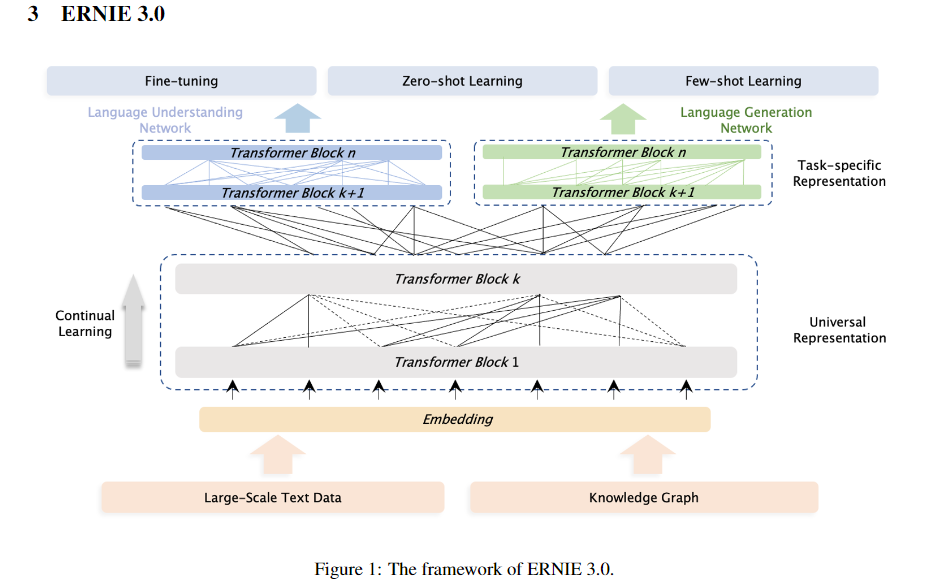
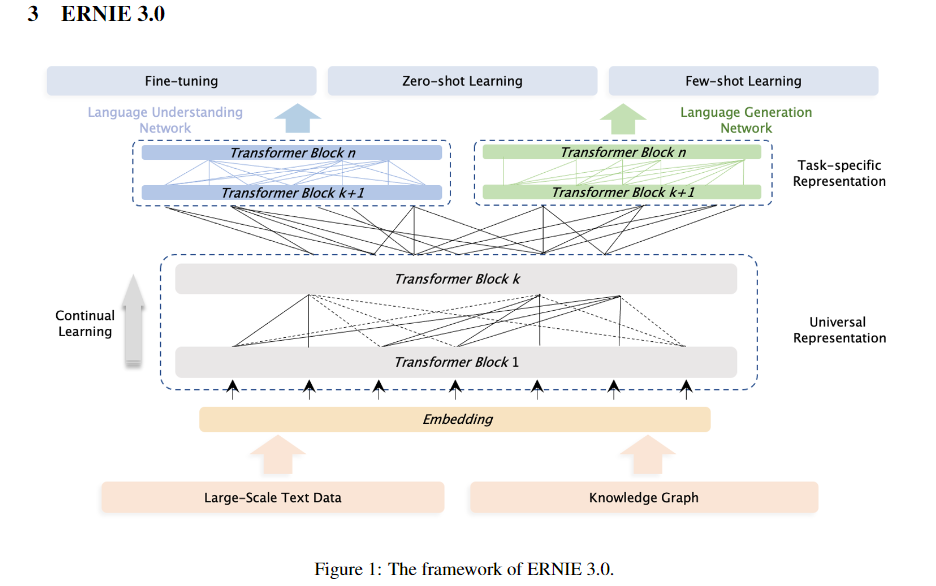
首先这是一个参数量比较大的模型,有一个通用的表示部分和 task-specific 部分,task-specific 部分针对不同的任务进行 fine-tune。
其他部分与 ERINE 1.0、ERINE 2.0 相似,例如训练时做 mask 像 ERINE 1.0 中的 整个部分进行 mask 而不是只对单个字独立地做 mask。 ERINE 2.0 的持续训练的方法也在这里面进行了使用。
模型主要创新
这个 3.0 的主要改进就在这里
引入知识图谱,对一句话进行三元组挖掘,经过对三元组的挖掘检测,然后再训练模型的时候,将挖掘的关系与原文拼接在一起进行输入。
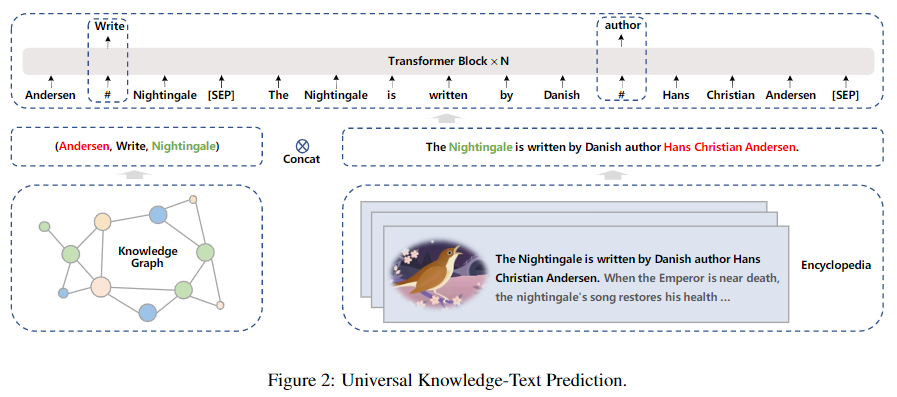
然后训练的时候主要使用了两种方法
- 将三元组中的某个实体或者关系去掉,然后通过B段去预测A段的masked部分。
- 将B段的某个实体去掉,通过A段去预测B段被masked的部分。
那么通过A理应可以预测B的缺失部分,而通过B也应该可以预测A的缺失部分。如果缺失部分是和语义(知识)有关的,那么模型应该可以学习到一定的知识才对。因此在ERNIE 3.0中作者称之为“知识图谱加强”。