How Can We Know What Language Models Know?
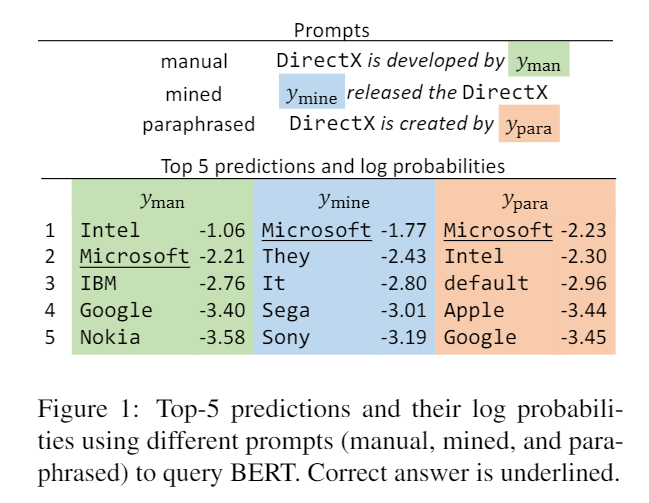
在生成任务中,只用不同提示会带来不同的效果。
例如在 LAMA 任务上,LAMA数据集中包含的句子用于描述两个实体之间的关系,而其中一个实体被遮盖,需要语言模型来预测,如果预测正确则说明模型学会了这一关系。
然而,很多时候其实从这些query中是看不出这种关系的,或者说,即便模型没有回答正确,也不能说明模型不懂这个关系。有时候是 query 是有问题的。
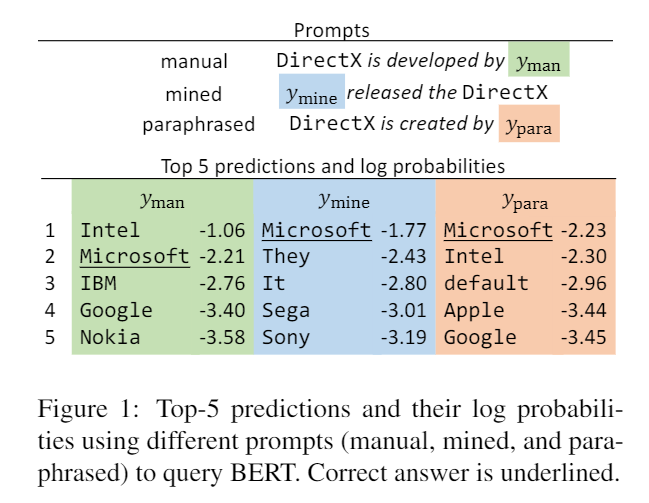
所以评测模型能学习到包含多少信息的时候,是不太准确的,由于不同的表述使得的出的结果会受到影响。
相关的测试很多时候只是测出模型效果的下限,那有没有让下限提高的办法?
既然不同的 Prompt 会影响后面的结果,那通过构建更好的 Prompt,会使得结果更好。
构建 Prompt 的方法
-
Mining-based
通过对语料进行挖掘,生成 Prompt。通过观察在庞大的语料库里面,主语和宾语附近的词通常用于描述这两者的关系。
-
Middle-word Prompts
根据观察,主语宾语之间的部分通常用来形容两者之间的关系。例如:Barack Obama was born in Hawaii。主语宾语之间的关系就为可以抽取出来,使用占位符替代主语宾语变为 x was born in y。
-
Dependency-based Prompts
存在主语宾语之间没有形容两者关系的这种类型的句子。例如:The capital of France is Paris。基于句子句法分析的模板对关系抽取更有效。使用依赖关系解析器识别主语和宾语之间最短的依赖路径。然后使用依赖路径中最左边单词到最右边单词的短语作为 Prompt。
上文的例子的依赖路径的例子如下:
箭头最左和最右的单词是 capital 和 Paris。通过这个生成的例子:capital of x is y。
用这种Mining-based的方式来生成 Prompt,可以涵盖可能的文本表达方式,但是也会比较容易产生噪声。因为这种方式获取的 Prompt,即使他们经常频繁地出现,可能也不是很好地能指示出主语和宾语之间的关系。
-
-
Parap_hrasing-based
目的是提高词汇的多样性,同时保持对原始 Prompt 的含义。具体做法就是将原始的 Prompt 换成相同意思的其他表述。
例如:x shares a border with y 就可以换成 x has a common border with y 和 x adjoins y。
与信息检索中使用的查询扩展类似,以此来提高检索的性能。
本文的具体实现是将 Prompt 翻译成其他语言,再翻译回来。将原始的翻译成成其他语言每种语言生成 个候选,再将 个候选翻译会原来的语言每个候选生成 个。将这 个根据概率 进行排序,然后保留 top T 个 Prompts。
Prompt 的筛选 和 汇合
Top-1 Prompt 的筛选
\mathcal{R} 是一组带有 的主语宾语 pair。
通过上面这种方式选出 accuracy 最高的 在这个 query 上只使用这个 Prompt
Rank-based Ensemble
不仅仅只是用 top-1,将多个 Prompts 组合起来使用。这样的优点是模型可以观察到训练集中不同的实体 Pair 在不同的上下文中的情况,各种各样的 Prompt 可以在不同的语境中使模型学到知识。
第一种 汇合的方法是 将 top-k 个 取平均。
Optimized Ensemble
上面的方法是认为每个 Prompt 是平等的,但是 Prompt 之间是有优劣的,所以可以进行一个加权。
其中
试验结果
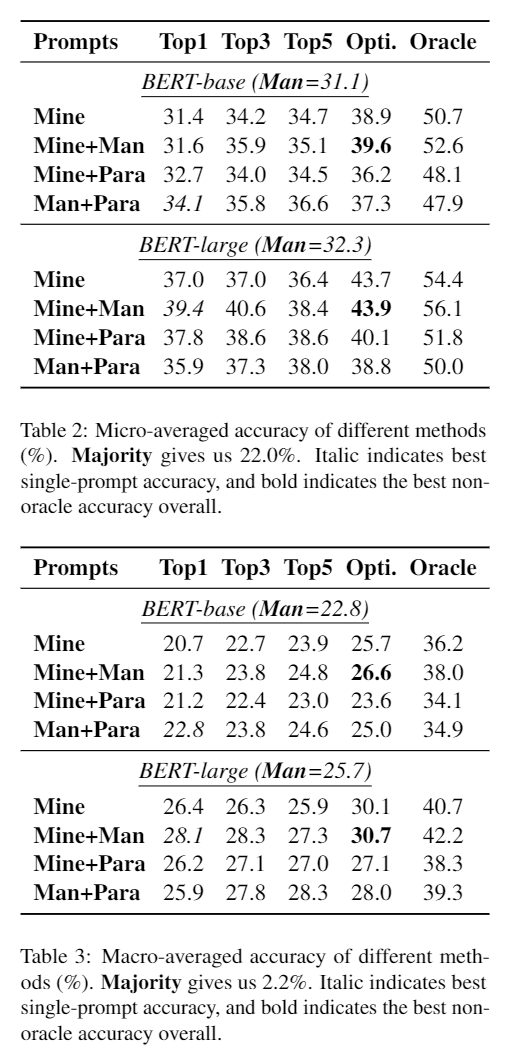
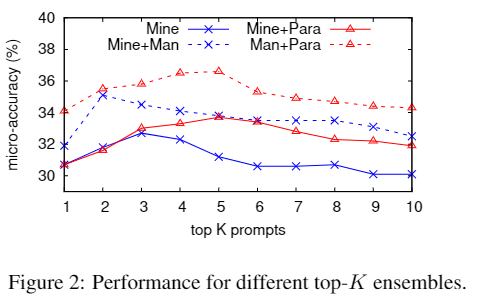
最后
总的来说,是一种数据增强的方法,不需要调整模型参数,并且效果也不错。可以提高在该任务上的模型的下限。