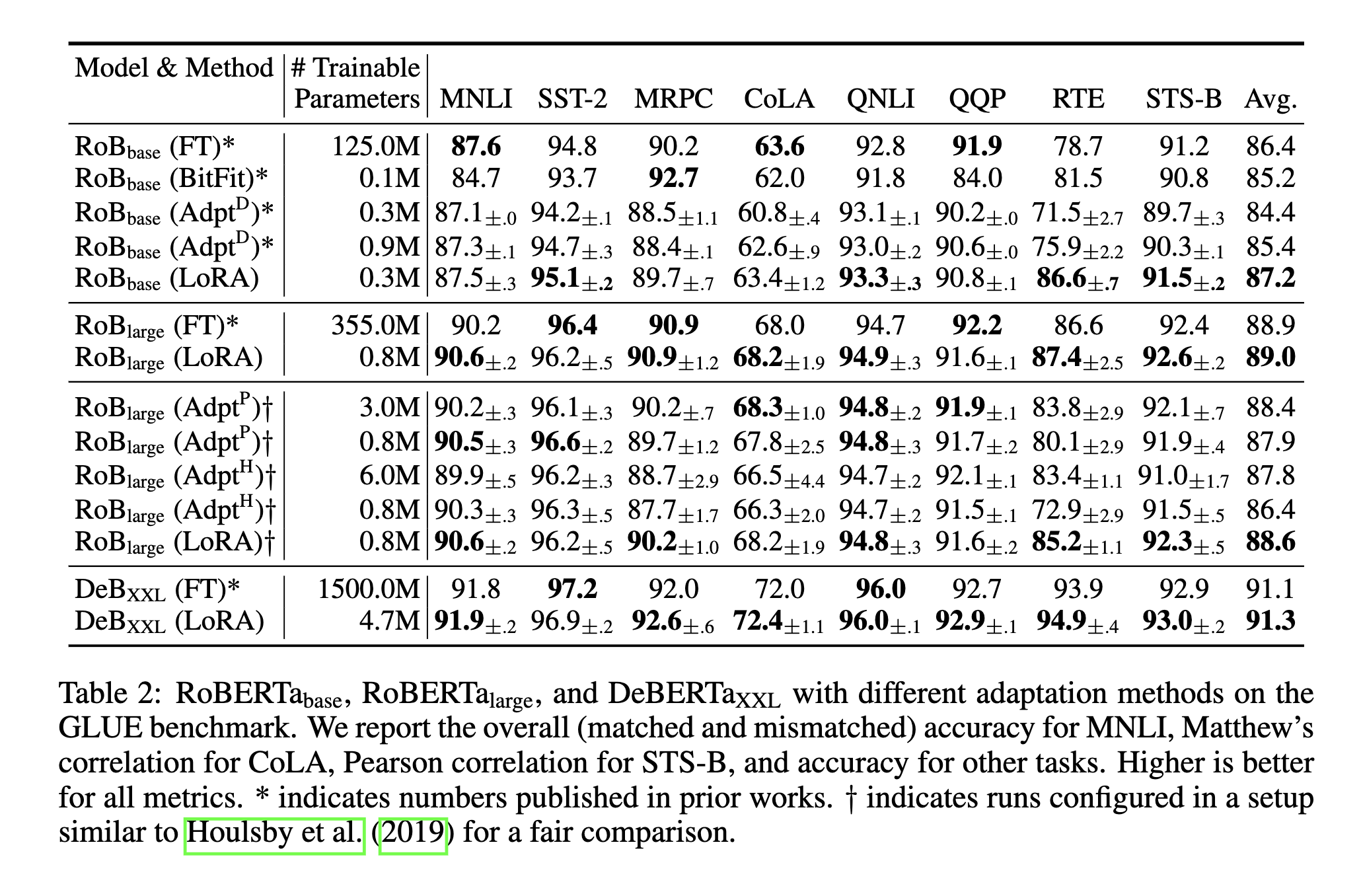
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
优点:
- 替换 A 和 B 就可以针对不同的任务进行切换
- 对硬件来说负担很小,需要计算梯度的只有插入的A、B部分
神经网络通常包含大量的全连接层,并通过执行矩阵乘法来完成前向传播。这些全连接层中的参数矩阵往往是满秩的。
作者证明了,预训练语言模型的参数中往往有一个较低的“本质维度”,即使待优化的参数矩阵被映射到一个较小的子空间内也能保持优秀的学习能力。
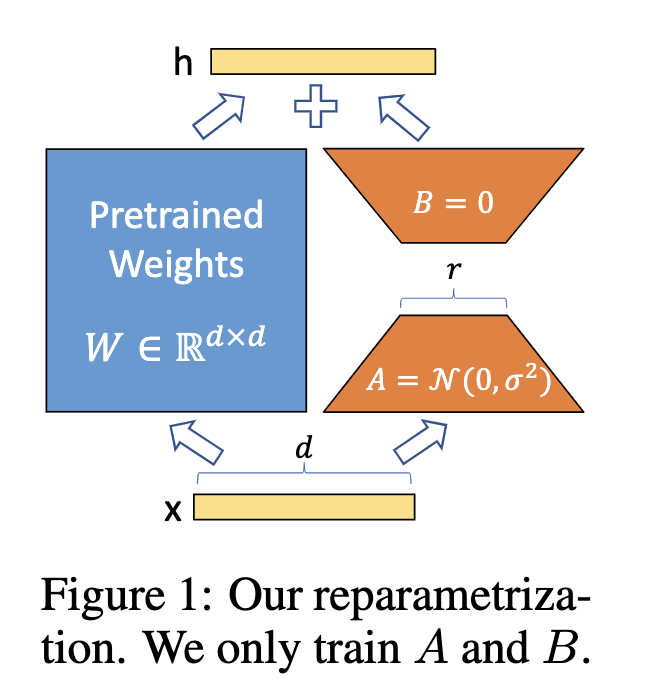
在这样的前提下,作者希望只对参数矩阵中低秩的部分进行优化,并将原矩阵的优化过程表示成一个低秩矩阵的优化过程:
预训练权重 (固定权重不更新)
adaptation 新增的参数
包含可训练参数
一开始 随机Gaussian initialization矩阵A,设置B=0,所以一开的
然后使用 对 进行缩放 是个常数