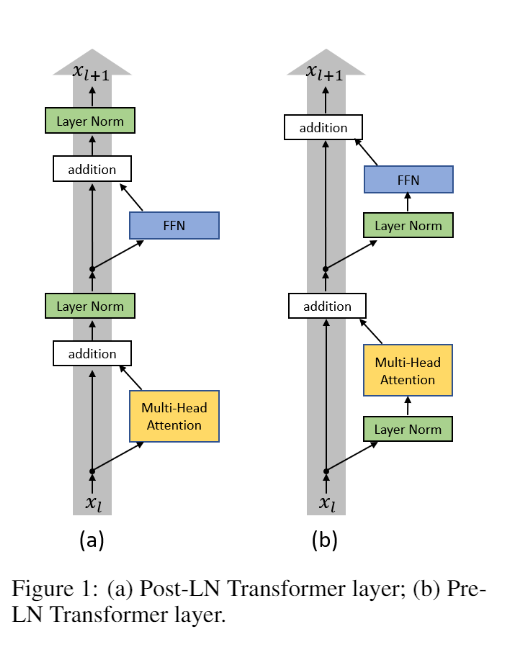
On Layer Normalization in the Transformer Architecture
- Post-LN: Layer Norm 放在 residual branch 之后
- Pre-LN: Layer Norm 放在 residual 过程中
Post-LN Transformer 中 warm-up 的重要性
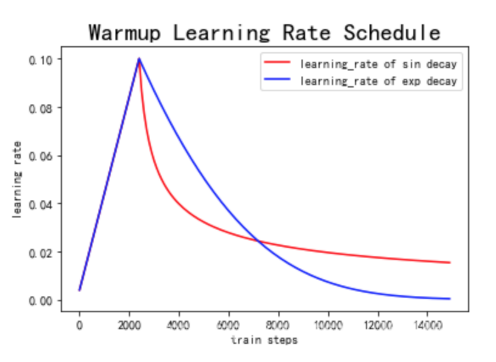
在机器学习训练中,通常学习率设置为常数,或者逐渐衰减。在训练 Transformer 时候一开始要将 learning rate 设置为接近0 然后再逐渐增大,之后再逐渐衰减。经过一定的迭代轮数后逐渐增长到初始的学习率,这个过程也被称作 warm-up 阶段。
warm-up 是原始 Transformer 结构优化时的一个必备学习率调整策略。Transformer 结构对于 warm-up 的超参数(持续轮数、增长方式、初始学习率等)非常敏感,若调整不慎,往往会使得模型无法正常收敛。
在 Post-LN Transformer 中输出层中的参数的预期梯度很大。所以如果不使用 warm-up 直接使用较大的 learning rate 来训练模型的话会使得模型没有优化,并且会导致模型的不稳定。
layer norm 在控制梯度的尺度中起决定性的作用,本文提出是否有一个更好的进行 layer norm 的位置,来获得更好的经过 layer norm 的梯度。
Pre-LN Transformer 在初始化的时候没有梯度消失和梯度爆炸的问题。本文尝试在训练 Pre-LN Transformer 的时候移除 warm-up,发现可以安全地移除 warm-up 。并且 Pre-LN Transformer 的 loss 下降更快。最终能够取得差不多的结果,但是使用的时间更短。
当采用 Xavier 方法对 Post-LN Transformer 进行初始化后,通过对各隐层梯度值进行分析可以证明,在初始化点附近的 Post-LN Transformer 结构最后一层的梯度值非常大,同时随着反向传播的进行会导致梯度值迅速衰减。这种在各层之间不稳定的梯度分布必然会影响优化器的收敛效果,导致训练过程初始阶段的不稳定。
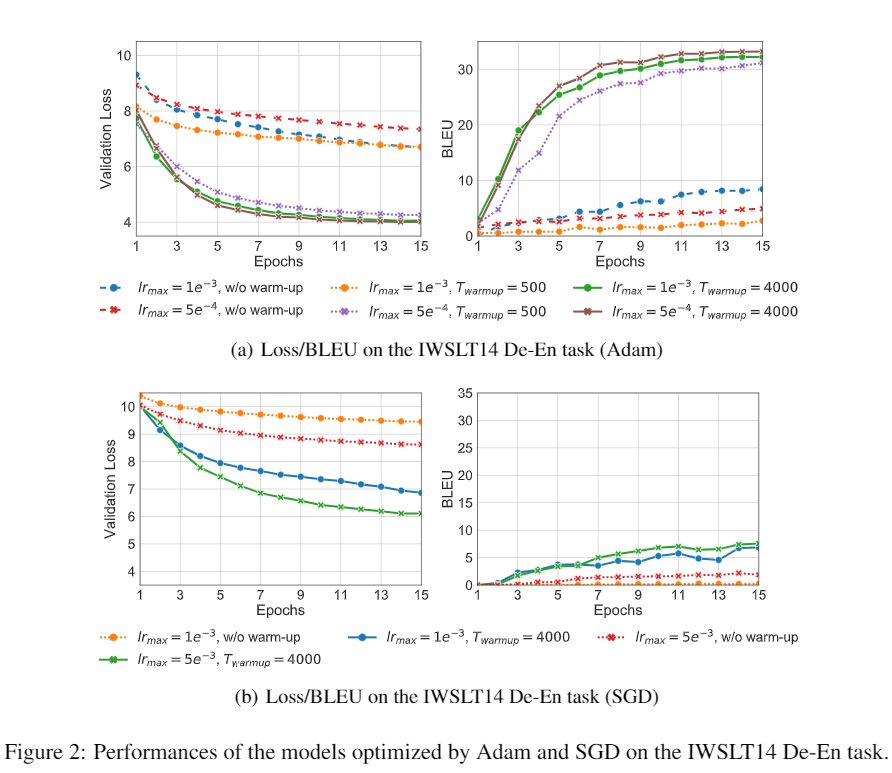
在一个德语-英语的翻译任务上进行实验,可以看出对于 Adam 和 SGD 在训练 Transformer 时,有 warm-up 都可以提升优化器的效果。warm-up 并不是特定地针对 Adam 才有效。
Gradients of the last layer in the Transformer
- L层 Post-LN Transformer 最后一层梯度
- L层 Pre-LN Transformer 最后一层梯度
Layer Norm 会 normalize 梯度,在 Post-LN Transformer 中,输入到最后一层LN的scale是与 $ L$ 无关的,因此最后一层的梯度也是与 $ L$ 无关的。而在Pre-LN Transformer中,输入到最后一层的LN的 scale 是随 $ L$ 线性增长的,因此梯度将会以 $ \sqrt{L} $ 的比例 normalized。