Parameter-Efficient Transfer Learning for NLP
目前大部分 NLP 任务都是用 Pre-train 再 fine-tune 的形式,虽然说fine-tune挺高效的了,但是在不同的下游任务上都要对模型进行fine-tune 花费的成本也挺高。
那么有没有一种方法,可以使得fine-tune 更为高效呢?
本文提出了 adapter tuning,使用adapter module,针对每个下游任务都只需要对少量的参数进行训练,就可以适应该下游任务。高效低进行参数共享。
适应下游任务的几种形式
假设有一个神经网络有参数 ,该神经网络可以表示为
-
feature-based
-
fine-tune
对原来的
进行重新调整 -
adapter-turning
只对 就行训练,通常是对网络添加新的层,但是只要 这就是很高效的做法。
Adapter Module
不是像 feature-based 那样只在最后面添加层,而是对模型中注入新的层。
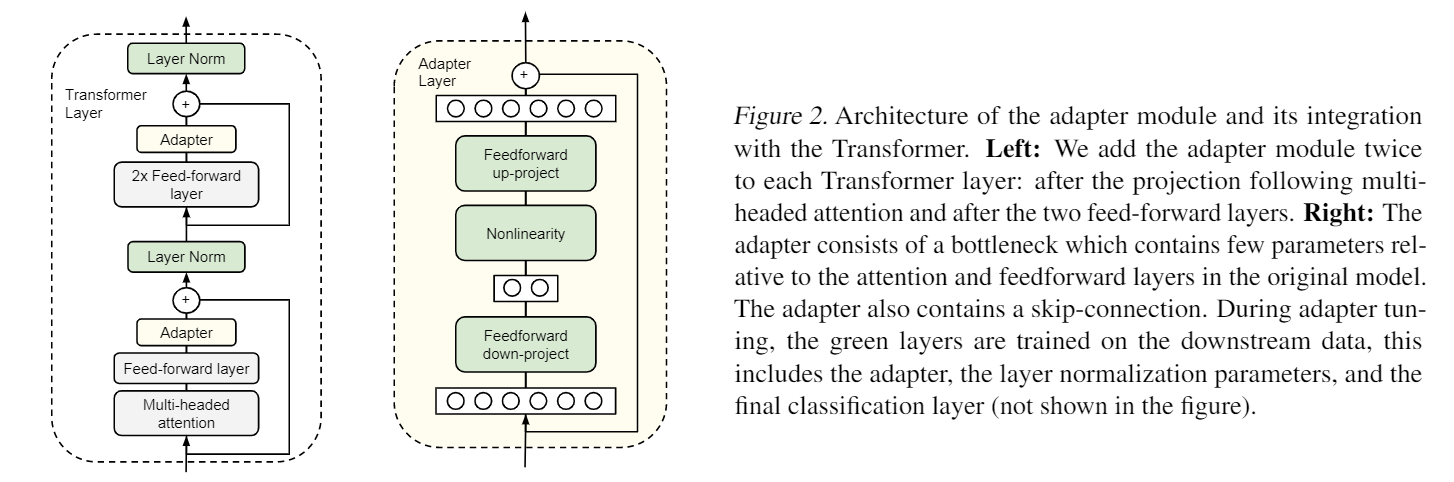
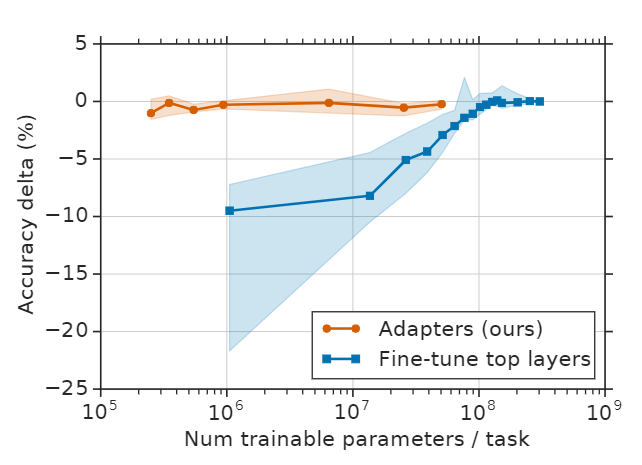
整体思路就是,在Transformer中添加 Adapter 模块。在GLUE 和 不同规模的文本分类任务上进行测试。
相比原本的 Bert-Large 在 GLUE,需要fine-tune 的参数量为 9X,而使用这种方法只需要 1.3X。
最后
这种方法还是挺有意思的,相比与原来的只在,freeze住模型,在输出最后叠加几层,从中间部分重新训练少量参数,利用原本的预训练模型,针对特定的下游任务可以快速迁移。很适合数据分布相同但是存在多下游任务应用不同的场景,可以快速完成不同下游任务的训练。