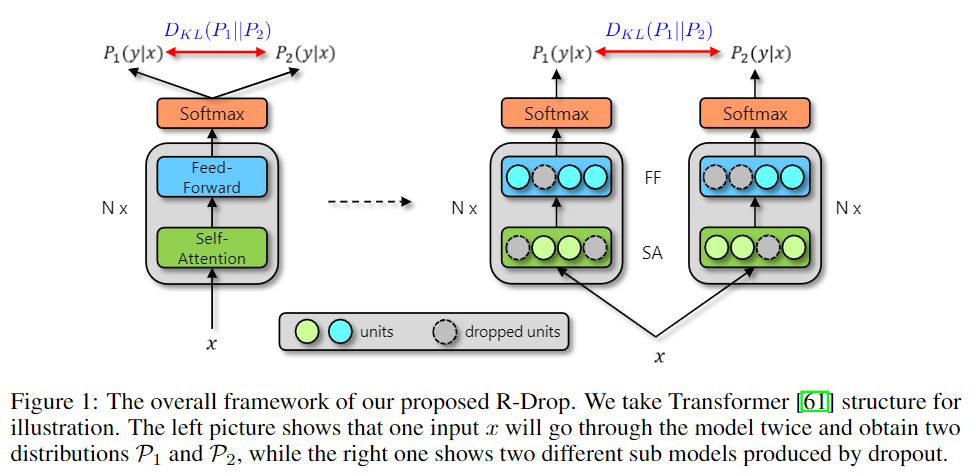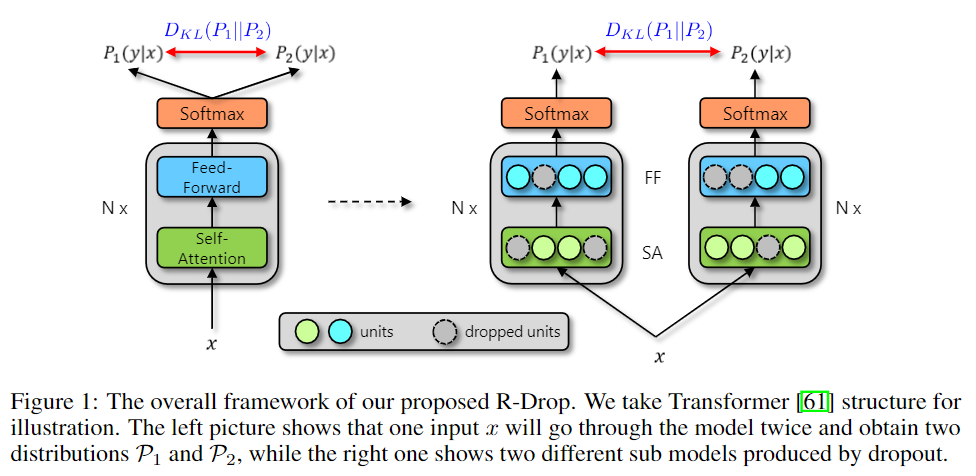
很简单的一篇,只要使用了 类似 dropout 这种带随机性的 layer。那么将同一个输入分别经过模型,那么会得到有差别的输出。
比如 dropout 来说,由于它的存在使得同一个输入分别经过模型时候,会使用不同的 sub models。导致输出结果的差异,但实际上我们是想要使用了不同的 sub models 也应该要有相同的结果。
所以这篇的思路就是在训练的时候,将一条数据分别经过不同的 dropout 的 模型,然后计算两个 输出的 KL散度,在原来的训练目标的基础上加上此 KL散度。
LKLi=21(DKL(P1w(yi∣xi)∥P2w(yi∣xi))+DKL(P2w(yi∣xi)∥P1w(yi∣xi)))
Li=LNLLi+α⋅LKLi
在翻译任务、Language Understanding、 Language Modeling、 Summarization、 Image Classification (ViT) 这些任务上都能取得效果的提升。