Understanding the Difficulty of Training Transformers
Transformer 训练比较难需要在设计合适的优化器和调节学习率上付出比较大的精力
本文发现,不平衡的梯度不是训练不稳的原因。相反,发现了 amplification effect 对训练影响比较大。
在多层 Transformer 模型中,每一层都严重地依赖 residual branch 使得训练变得不稳定,它会放大微小参数的扰动 (例如参数更新的变化),并对模型的输出造成明显的干扰。
根据分析的启发,提出了 Admin (Adaptive model initialization),来稳定训练的早期阶段同时在后期释放模型的潜力。
本文的分析是起源自发现:Post-LN (Post Layer Normalization) 比 Pre-LN (Pre Layer Normalization) 是 less robust 的。梯度消失并不是导致这个问题的直接原因,因为在解决梯度消失的问题后,并不能使得 Post-LN 变得稳定。这表明除了不平衡的梯度外,还有其他因素对模型的训练有很大的影响。
根据进一步分析本文提出,发现了对于每个 Transformer residual block 依赖于它的 residual branch, residual branch 对训练的稳定性起决定性作用。
Post-LN 依赖 residual branch 比依赖 Pre-LN 更多,Post-LN 的强烈依赖性会放大参数变化带来的扰动,并破坏训练的稳定性。此外,Pre-LN 对 residual branch 松散的依赖会限制算法的潜力,往往导致训练成较差的模型。
本文提出的 Admin 在训练的早期限制了对 residual branch 的依赖性,并在后期释放模型的潜力。
- Post-LN: Layer Norm 放在 residual branch 之后
- Pre-LN: Layer Norm 放在 residual 过程中
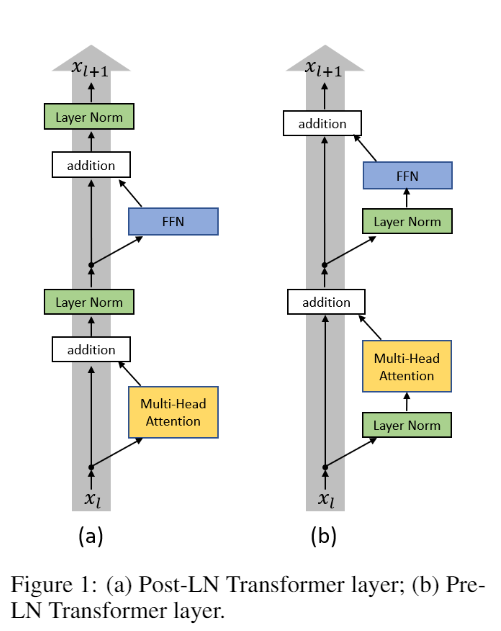
Pre-LN 在训练时比 Post-LN 具有更好的 robust,但是 Post-LN 比 Pre-LN 更可能达到更好的效果。
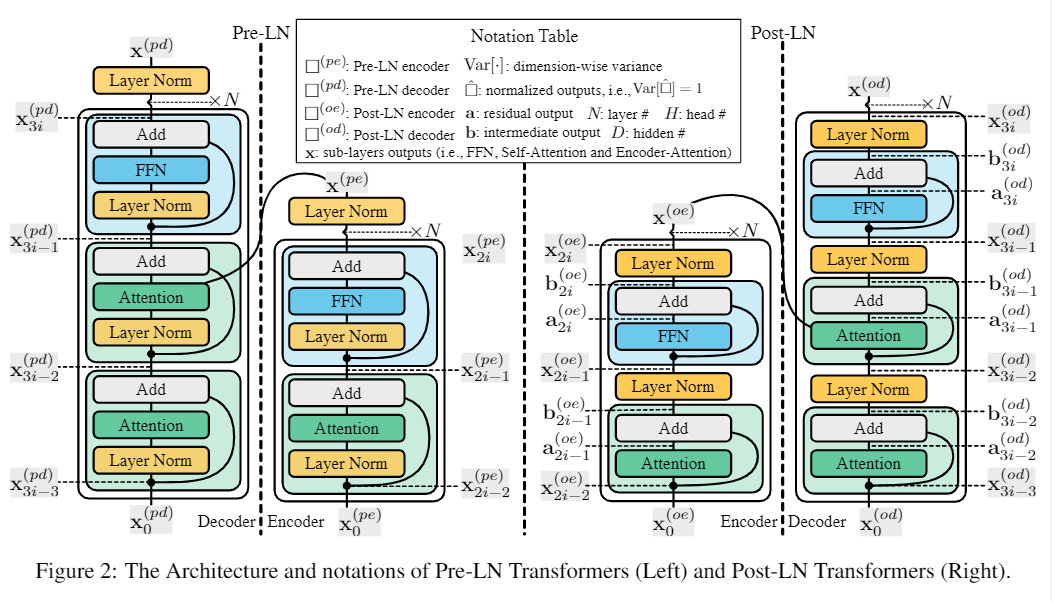
Post-LN decoders 存在 梯度消失的问题,而 Post-LN encoders 没有这个问题。将梯度消失的问题解决也不能使训练稳定。
Transformer 即使使用了 residual connection 也会存在梯度消失的问题。
通过使用混合Post-LN 和 Pre-LN 的模型进行实验,证明只有 Post-LN decoders 存在梯度消失的问题,Post-LN encoders、 Pre-LN encoders、 Pre-LN decoders 不会有这个问题。
并且所有类型的模块都是不平衡的。
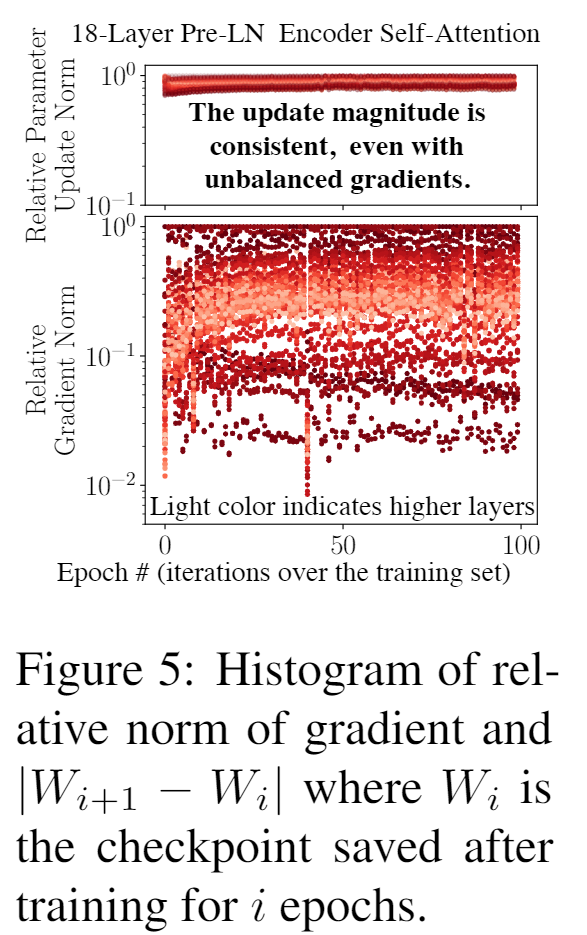
自适应的优化器成功地将不同的学习率分配给不同的参数,即使在不平衡的的梯度下也可以使更新的幅度一致。这解释了 SGD 优化器在训练 Transformer 时效果差的原因,无法较好地解决不平衡梯度的问题。
初始化时候的放大效应 (Amplification Effect)
尽管对 residual branch 的依赖更大模型会有表现效果的潜力。但是它放大了参数变化带来的波动。
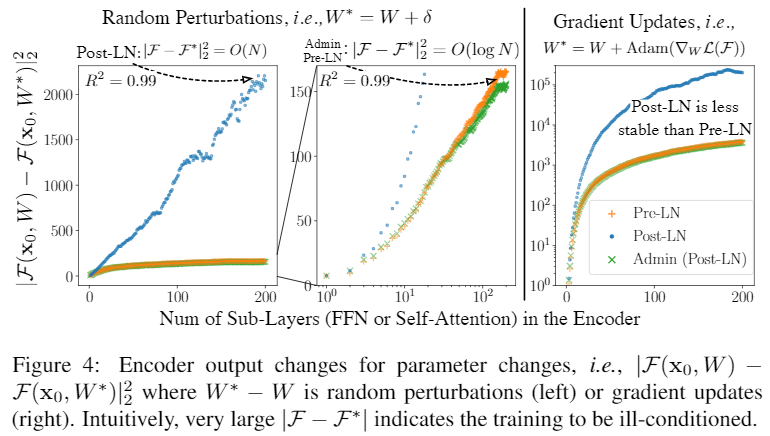
Admin (Adaptive Model Initialization)
通过在训练的早期对 residual branch 的依赖进行控制。由于不同的训练参数和模型特性,很难推导通用的初始化方法。